
摘要:作为一名“AI思想家”,尼克·奥特战士经常出现在全球各大高新科技、经济活动的发言台,言必称“算率”。 我还在《黄仁勋“人肉快递”,掀起900亿美元算力争夺战》中也提到,由来只不过二种途径:买和自主研发。如今,美……
作为一名“AI思想家”,尼克·奥特战士经常出现在全球各大高新科技、经济活动的发言台,言必称“算率”。
我还在《黄仁勋“人肉快递”,掀起900亿美元算力争夺战》中也提到,由来只不过二种途径:买和自主研发。如今,美国硅谷巨头们基本上都是双轨并行,一边买、一边结局自主研发,连水果也被传出和tsmc做了4年推理芯片新项目ACDC(Apple
Chip in Data Center)。
流行GPU经销商包含英伟达显卡、AMD、Intel这三家,但是每个上百万颗GPU可以制作出来的前提条件,是上下游的服务商可以提供充足的零部件,例如最为关键的HBM内存芯片。
以H200为例子,1颗逻辑芯片要搭配6颗HBM内存芯片,到GB200,1颗逻辑芯片要搭配8颗HBM内存芯片,整体需求会在现有前提下提高30%之上。TrendForce预估2025年GB200的销售量有望突破100千颗,仅仅这一款产品,对HBM保存的要求就把做到800千颗。

01 AI带红HBM
HBM(High Bandwidth
Memory),汉语翻译来即带宽测试运行内存,因为这些年的GPU商品大量选用而红起来(如下图所示),可事实上它还不算特别新的概念,2013年便被固体技术协会精准定位国家标准。
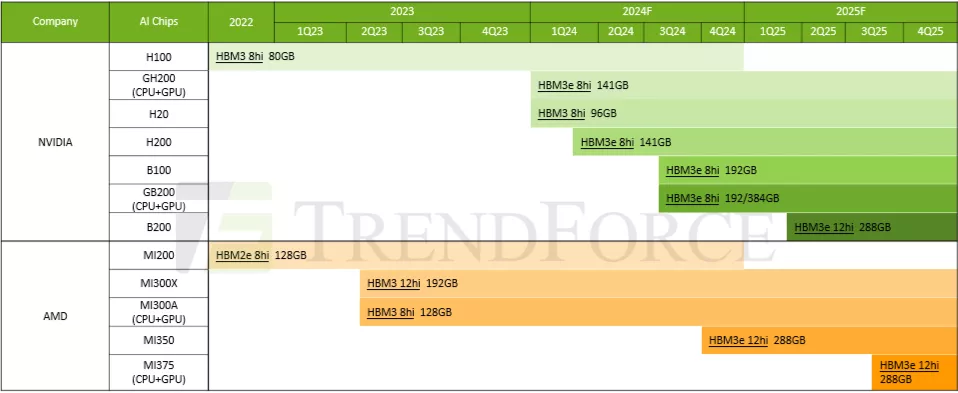
关键GPU生产商的主流产品相对应的HBM型号规格,由来:TrendForce
2015年,AMD Radeon R9 Fury
X整个行业初次运用HBM运行内存,但是由于那时候深度神经网络空间向量测算要求都还没暴发,且HBM与GPU/CPU封装形式在一起,对比DDR内存空间年纪还小,做为初期技术性成本很高而难以在消费级商品上大规模运用。
高到什么地步?AMD RX Vega那时候搭载的是2颗HBM2运行内存,BOM成本费应该是160美金,单珠成本费80美金,数倍于GDDR5
/
GDDR5X,TrendForce预计HBM的标价是DDR的5倍,并且HBM的价钱伴随着算力需求的上升也在不断地增涨,这个差距还会进一步放大。
贵,还只能用,难点在于处理器和运行内存之间的数据互换存有短板。
对比热门的存储方案,HBM的带宽测试,在处理数据传输短板上有着天然的优势。依据Embedded搜集的数据信息,16GB的HBM2e每一个局部变量的上行宽带做到460.8GB/s。
架构上,传统式计划方案一般为存算分离出来架构设计,处理器是Cpu,内存是运行内存,存放微粒逻辑芯片分离,而使用3D层叠的HBM运行内存,也可通过CoWoS与逻辑集成电路芯片在一起。

1GB GDDR5和1GB HBM的die size比照,由来:互联网
在视觉上来说,CoWoS封装的立即盈利便是GPU尺寸比较小,自然HBM运行内存自身规格就很小,同是1GB存放,GDDR5尺寸大约在672mm²,而HBM仅有35mm²,差别贴近20倍。
这类规格上的差别,在PCB板里表现得更加明显,例如R9
290X,处理芯片+运行内存搭配PCB板面积达9900mm²,而使用CoWos封装形式计划方案,占地面积不上4900mm²,占PCB板总面积减少了近一半。

GDDR5与HBM存放特性差别,由来:AMD
根据3D层叠和CoWoS封装形式,HBM的显卡内存网络带宽获得了很大的提升,2015年,AMD官方网带来了一张HBM和GDDR5参考的PPT(如上图所述),AMD将HBM称作“一种有别于GDDR5的内存”,清晰的描写了根据硅通孔(TSV)科技的HBM运行内存,当政宽、网络带宽及其工作标准电压上二者的差别。
一句话简略汇总,HBM克服了很多数值计算面临的最最核心的网络带宽难题,另外在尺寸大小功能损耗要比GDDR5也有明显的优点。
02 3000美金,HBM成本费占一半
纯粹说HBM内存价格贵,你可能会没概念,假如将其放在全部GPU成本里来说,就更直观了。
H100的BOM成本费预计3000美元左右,80GB的HBM存放大概1500美金,即18.75美金/GB,最核心的逻辑芯片大概300美元左右,SXM模块费用在300美金下列,封装基板和CoWoS大概300美金。
换句话说,保存的成本费用占一颗GPU材料成本的一半。
现阶段,流行经销商都加速提产节奏感,SKsk海力士预计明年生产能力会翻一倍。三星则更为激动,在今年的CES上,三星预计全年HBM生产能力将进一步提升2.4倍,到3月底MEM会议上,又将这一预估拉升到2023年的2.9倍,而2026年和2028年,分别将提升到2023年的13.8倍和23.1倍。
SKsk海力士、三星和美光科技们拉升HBM的产能解决GPU客户需求,但是今年和下一年的目前生产能力基本都被抢空。
上年12月份,韩媒体披露称英伟达显卡向SKsk海力士和美光科技下13亿美元订单信息,而著名硬件配置网址tomshardware引用这则消息,测算称该笔费用预算大致在10.8
亿美金到 15.4 亿美金中间,而且是为了保证H200该产品的HBM供货安全性。
按前边的BOM成本费,一颗GPU搭配6颗HBM成本为1500美金,该笔费用预算也只能满足86.6千颗H200的HBM运行内存要求。
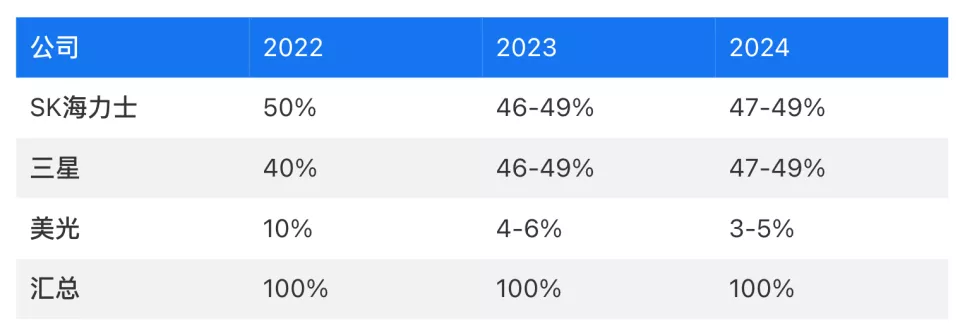
2022-2024 HBM市场占有率,由来:TrendForce
TrendForce上年8月份整理过近三年HBM市场占比状况(如以上),SKsk海力士和三星一直是市场中的主人公,在其中SKsk海力士是英伟达显卡HBM3的主力军经销商,三星则主要面向别的云厂,却也刚已通过英伟达显卡的供应商认证,二者占据着绝大多数市场占比,美光科技的总体市场占有率大致在5%上下。
分割到具体产品上,TrendForce觉得,在今年的HMB3依旧是市场主流,市场占有率将于60%之上,8层及12层HBM3e的总计市场份额大约在25%上下。
先前SKsk海力士向社会公布,在今年Q2逐渐少许交货12层层叠的HBM3e,美光科技确定3月份逐渐交样,三星则将在9月份逐渐向英伟达显卡供应(GTC上黄仁勋归还三星的12层层叠HBM3e签字:Jensen
huang验证)。
这就意味着,三家经销商将在三季度拉响HBM3e销售市场争霸战,规模性供应产品类别。
市场需求旺盛,价钱也会跟着跟随起降。
TrendForce的投资分析师Avril
Wu引用全产业链的消息称,2025年的HBM标价商谈早就在今年第二季度逐渐,受制于DRAM产能的不够,核心供应商明确表示价格上涨,上涨幅度预计5%-10%中间。而涨价原因可以归结为三个:客户需求充沛、HBM3e的合格率偏降低成本高及其供应商产能和稳定性区别。
但是,根据DRAM的HBM大幅度提产,还会间接的缩小其它产品的产能,这也就意味着消费级市场已经可能面临冲击性,TrendForce预测分析最大上涨幅度会达到20%,那么接下来AI
PC假如价格上涨,代表着那你也要为AI产业发展买单。
03 国内HBM更快来年面世
HBM也是提产,也是价格上涨,国内现状如何,这大概是好多人关注的话题。
这种情况大概能够从两个方面来说,最先,是国产GPU是否能购买到HBM运行内存;次之,是国产HBM进度如何?
依据公开信息,已有国内GPU使用HBM运行内存,但是优秀产品产能比较有限,国内选购的主要是前两代为主,例如HBM2e。此外,受限于BIS限制,产品类别不能直接根据SKsk海力士、三星和美光科技立即供应,但可以通过一些独特方式从以上经销商在全球的代理商的方式购置,随后组合控制板、逻辑芯片,运用CoWoS进行GPU的封装形式。
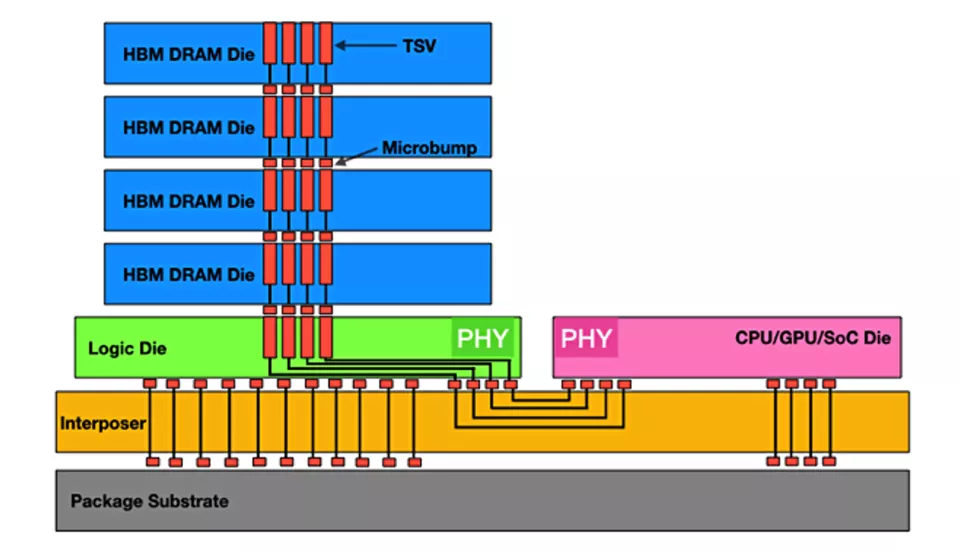
CoWoS封装形式截面,在其中深蓝色为3D层叠的HBM运行内存,翠绿色为主板芯片,粉红色为逻辑芯片,橘色为硅中介公司层,深灰色为封装基板,由来:Rambus
除开独特方式购置HBM运行内存,可以直接购置DRAM颗粒物,但是这必须原装预埋TSV孔,这样有利于运用国内线进行层叠封装形式HBM,当然你也可以采购裸晶封装形式成DRAM颗粒物,然后通过TSV硅通孔技术性,层叠封装形式变成HBM运行内存,重复利用国内CoWoS生产能力,进行GPU封装形式。
和tsmc少数几个生产商的全链条CoWoS封装形式能力不同,大陆封装形式分成CoW和WoS两部分,由不同生产商进行。但是,在生产能力不好的情况下,台积电的一部分CoWoS还会分解成这样的方式,例如tsmc进行CoW一部分,再由日月色,Amkor等厂商进行WoS的那一部分。
根据此前全产业链信息,Amkor已经进入到英伟达显卡的供应商体系之中,取得L40S的封装形式订单信息,同样在合理布局CoWoS封装形式,如果将来英伟达显卡订单在tsmc加利福尼亚厂家生产,又因为tsmc在国外都还没先进封装生产线,这一部分订单信息很有可能被Amkor取得。
回归正题,将CoWoS分解成CoW和WoS两个部分,关键就在于工艺技术成熟情况,其次两个部分的合格率的同步,这应该是现阶段的挑战之一,需要长时间的Know
how及其合作,来提高合格率、降成本。
有关国内HBM进展如何问题,实质上是回应国内HBM
DRAM颗粒物纯自研的进度,现阶段合肥市、武汉市、泉州市和深圳都是有相关产业在布局,前三地的生产商很多人应该了解,深圳市昇维旭归属于当红入局者。
2022年3月份,深圳市昇维旭创立,对焦通用性DRAM芯片设计研发,同一年6月官方宣布日本半导体材料教父3、尔必达院长坂本幸雄担任首席战略官,令人遗憾的是坂本幸雄已于今年2月14日因心梗过世,终年76岁。
据芯事多重专栏作者Morris
Zhang表露,昇维旭预计最快来年可以拿出有关实用化SKU,第一代商品有可能在相对较高的连接点层叠,颗粒密度小一些,工作频率/位宽/网络带宽规格型号小一些。
此外,一些国产厂商也在进行更完善的晶体三极管构造科学研究,例如在去年年底69届IEEE国际性电子元器件年度会议,长鑫发布了一篇简述环绕式闸极构造GAA(三星3nm连接点导进的架构)技术性论文,被看做是提升3nm加工工艺。
客观地说,毕业论文实质上只是一种技术性展现,与科技突破不可以画等号,且长鑫也发出声明,称毕业论文叙述了与DRAM结构与4F²存储器总体设计可行性分析有关的基础研究(对比现阶段6F²构造,运用4F²构造,在不影响工艺节点的情形下,能够实现封装尺寸微型30%),与现有生产工艺不相干。
长鑫的回复合乎中国芯片状况的客观性逻辑性,今天就场均三双SKsk海力士、三星这种存放大佬基本不可能,但是其反映出来的发展趋势很重要——国产厂商当面对诸多挑战的情形下,仍在持续投入优秀存放技术的研究,这应该是真正应该感到开心一个点,终究这才是真正国内存放,甚至中国芯片产业链的火苗与希望。










